
Training
Train models through the training UI.Selecting your training set
You need just a few images:- Faces/objects: 4-10 images usually sufficient
- Styles: Can use hundreds or thousands for diverse styles
- Tips for training images
- Custom prompts (optional)
- Selective diversity: Maximize variance of everything you’re not trying to learn
- High resolution: At least 768x768 pixels
- Center-cropped: Target subject should be in center square
- Prominence: Feature target prominently
Training parameters
Model types
Faces
Optimized for human faces. Use object mode for non-human faces. Reference in prompts:
Reference in prompts:
- Xander as a character in a noir graphic novel
- Xander as a knight in shining armour (using angle brackets)
- Xander as the Mona Lisa (using angle brackets)

Objects
For all “things” besides human faces: physical objects, characters, cartoons. Prompt examples:
Prompt examples:
- a photo of kojii surfing a wave (using angle brackets)
- kojii in a snowglobe
- a low-poly artwork of Kojii

Styles
Model artistic styles or genres, focusing on abstract characteristics rather than content. With style models, you don’t need to reference the concept - just prompt normally and the style will be applied.
With style models, you don’t need to reference the concept - just prompt normally and the style will be applied.
 Styles can capture various aesthetics, color palettes, layout patterns, or abstract notions like knolling:
Styles can capture various aesthetics, color palettes, layout patterns, or abstract notions like knolling:


Generating with models
Once trained, select your model in the creation tool and trigger it by name or<concept> in prompts.
Exporting Models
Eden models are compatible with other tools supporting LoRA.
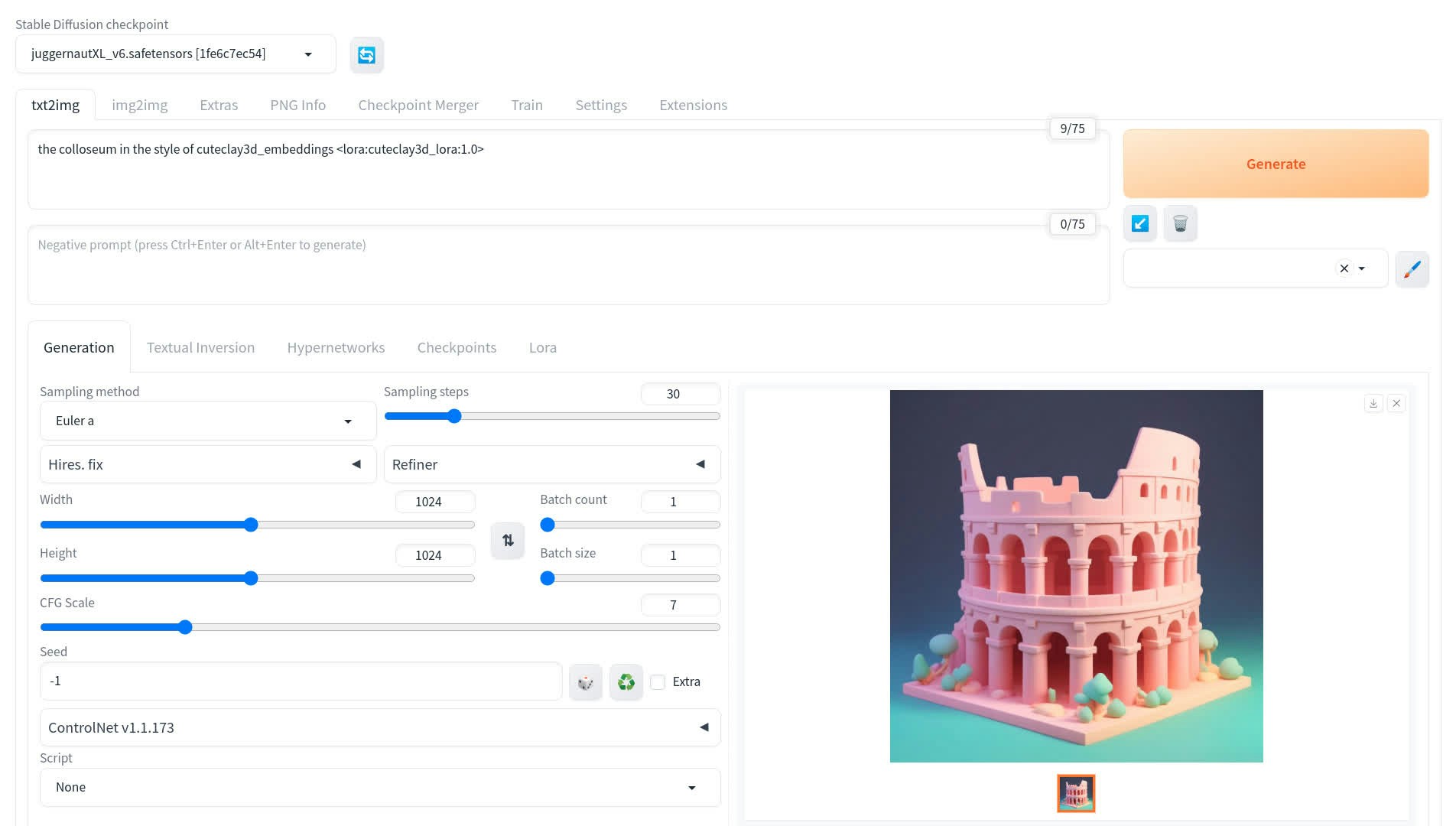
AUTOMATIC1111
1
Download and extract
Download concept and extract the .tar file
2
Install files
- Put
[lora_name]_lora.safetensorsinstable-diffusion-webui/models/Lora - Put
[lora_name]_embeddings.safetensorsinstable-diffusion-webui/embeddings
3
Configure
Use JuggernautXL_v6 as base checkpoint
4
Trigger in prompt
Load both embedding AND LoRA weights by triggering in prompt
ComfyUI
1
Install files
- Put
[lora_name]_lora.safetensorsinComfyUI/models/loras - Put
[lora_name]_embeddings.safetensorsinComfyUI/models/embeddings
2
Load LoRA
Use “Load LoRA” node and adjust strength
3
Trigger model
Reference with
embedding:[lora_name]_embeddings in prompt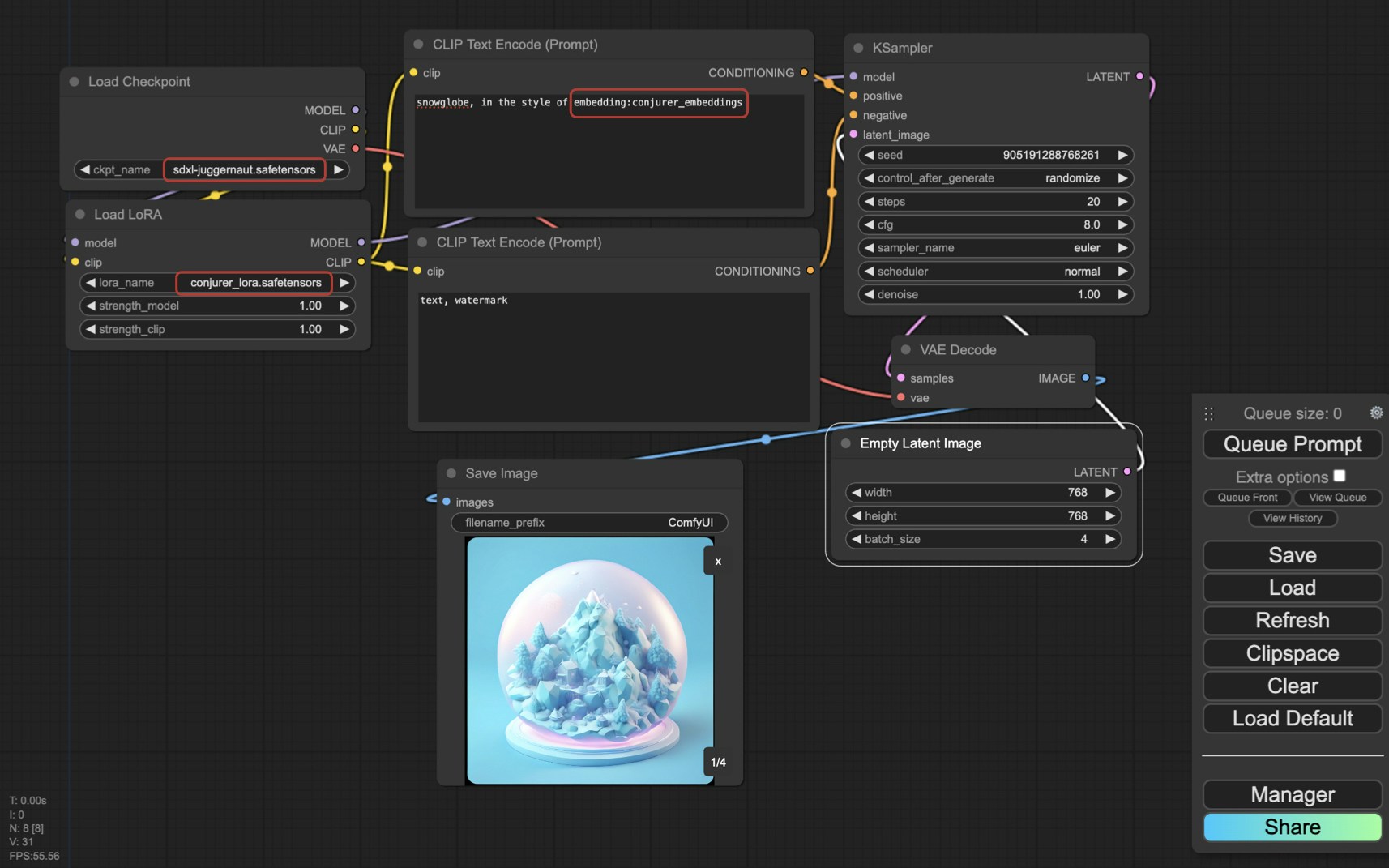
LoRA strength has relatively small effect because Eden models optimize token embeddings rather than LoRA matrices.